集成模型XGBoost 機器學習熱門研究方向入門指南與學習路線圖
引言
在當今人工智能(AI)和機器學習的浪潮中,集成模型憑借其出色的預測性能和穩定性,成為了眾多研究與應用領域的核心工具。其中,XGBoost(eXtreme Gradient Boosting)以其卓越的效率、靈活性和在各類數據競賽(如Kaggle)中的統治性表現,穩居最熱門的研究方向之一。無論是希望入門機器學習的新手,還是尋求進階的開發者,掌握XGBoost都至關重要。本文將為你系統性地梳理XGBoost的核心概念、應用優勢,并附上一份清晰的學習路線圖,助你從入門到實踐。
第一部分:XGBoost是什么?為何如此重要?
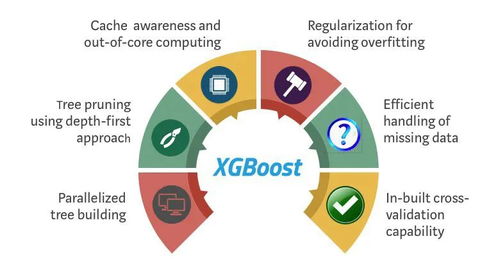
XGBoost是一種優化的分布式梯度提升庫,屬于集成學習中Boosting家族的一員。其核心思想是串行構建多個弱學習器(通常是決策樹),每一個新模型都致力于糾正前一個模型的錯誤,最終將這些模型的結果加權求和,得到一個強大的強學習器。
其重要性體現在以下幾個方面:
1. 高性能:在許多結構化數據(表格數據)的分類和回歸任務中,XGBoost的表現常常優于深度學習等復雜模型。
2. 高效靈活:算法設計上進行了大量優化(如稀疏感知、并行處理、緩存優化),訓練速度快,能處理大規模數據。支持自定義目標函數和評估準則。
3. 廣泛的適用性:在金融風控、廣告點擊率預測、商品推薦、疾病預測等眾多領域都有成功應用。
4. 可解釋性:相比“黑箱”深度神經網絡,基于樹的集成模型能提供特征重要性評分,有助于理解模型決策過程。
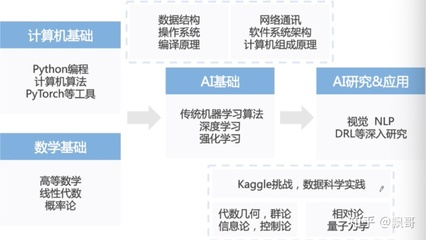
第二部分:XGBoost核心概念快速入門
在深入學習前,你需要理解幾個關鍵概念:
- 梯度提升(Gradient Boosting):通過梯度下降來最小化損失函數,指導新樹的生成方向。
- 決策樹(CART):XGBoost的基學習器,用于進行特征分裂和預測。
- 正則化:XGBoost在目標函數中引入了正則項(L1/L2),用于控制模型復雜度,有效防止過擬合。
- 特征重要性:通過計算特征在樹結構中被用于分裂的次數或帶來的增益,評估其對預測的貢獻。
- 超參數:如學習率(
eta)、樹的最大深度(max_depth)、子采樣比例(subsample)等,對模型性能有決定性影響,需要通過調優(如網格搜索、貝葉斯優化)來確定。
第三部分:XGBoost學習路線圖
以下是一個循序漸進的學習路徑,結合理論學習與實踐編碼:
第一階段:基礎準備(1-2周)
1. 掌握前置知識:確保你具備Python編程基礎、NumPy/Pandas數據處理技能,以及對機器學習基本概念(如監督學習、過擬合/欠擬合、交叉驗證)的理解。
2. 環境搭建:安裝Python科學計算環境(推薦Anaconda),使用pip install xgboost命令安裝XGBoost庫。
第二階段:核心學習與實踐(2-3周)
1. 官方文檔與教程:從閱讀XGBoost官方文檔開始,這是最權威的學習資源。重點關注Python API介紹和參數說明。
2. 動手實踐:
- 第一步:在CSDN、Datawhale等社區或博客平臺,尋找一個完整的XGBoost分類/回歸入門項目(如使用經典的泰坦尼克號生存預測或波士頓房價數據集)。跟隨教程,完成數據加載、預處理、模型訓練、預測和評估的完整流程。
- 第二步:深入理解關鍵超參數,并嘗試使用
GridSearchCV或RandomizedSearchCV進行調優,觀察模型性能變化。
- 第三步:學習使用XGBoost的可視化工具,如繪制特征重要性圖和單棵樹的結構圖,增強模型理解。
第三階段:進階與深入(長期)
1. 理論深化:閱讀陳天奇(XGBoost作者)的原始論文《XGBoost: A Scalable Tree Boosting System》,深入理解算法原理、系統設計和優化細節。
2. 對比學習:了解與XGBoost相關的其他集成模型,如LightGBM(微軟出品,速度更快)和CatBoost(擅長處理類別特征),理解它們的異同與適用場景。
3. 參與項目與競賽:
- 在Kaggle、天池等數據競賽平臺上,尋找使用XGBoost/集成模型的比賽,通過實戰提升工程能力。
- 將XGBoost應用到你的專業領域或感興趣的課題中,解決實際的預測問題。
- 關注前沿:通過關注AI頂會(如NeurIPS, ICML, KDD)和優秀博客,了解集成學習和樹模型的最新研究進展(例如,在深度學習中結合樹模型的研究)。
第四部分:資源推薦
- 優質社區與博客:
- Datawhale:一個開源學習組織,經常發布優質、系統的機器學習學習資料和組隊學習項目。
- CSDN博客:擁有海量中文技術博客,搜索“XGBoost 詳解”、“XGBoost 實戰”等關鍵詞,可以找到大量由從業者分享的實踐心得和代碼示例。
- 在線課程:吳恩達的《機器學習》課程、李宏毅的《機器學習》課程中均有涉及集成學習的內容。
- 書籍:《機器學習實戰:基于Scikit-Learn、Keras和TensorFlow》等書中對集成模型有詳細介紹。
###
XGBoost作為機器學習工具箱中的一把利器,其價值已在工業界和學術界得到充分驗證。學習它,不僅僅是掌握一個算法庫,更是理解集成思想和模型優化實踐的絕佳途徑。學習之路始于足下,建議你立即按照上述路線圖,從運行第一個“Hello World”般的XGBoost程序開始,逐步構建起自己的知識體系與實踐能力。在人工智能基礎軟件開發的廣闊天地里,精通XGBoost將為你增添一項極具競爭力的核心技能。
---
(注:本文內容整合了人工智能領域常見的學習路徑與資源,旨在為初學者提供一個清晰的指引框架。具體學習時,請以官方文檔和經典資料為準,并結合大量動手實踐。)
最新產品